Instrukcja
Wprowadzenie
Dane korpusu są dostępne w dwóch wyszukiwarkach. Pierwsza to wyszukiwarka segmentów (w przybliżeniu: słów), w której teksty korpusu mogą być przeszukiwane za pomocą elastycznego języka zapytań uwzględniającego wielowarstwowy opis lingwistyczny, a wynikiem tego wyszukiwania są słowa prezentowane w kontekście, w którym występują. Ponadto dostępna jest wyszukiwarka tekstów, w której można pobrać całe teksty znalezione na podstawie metadanych.
Wyszukiwanie segmentów
Wyszukiwanie segmentów polega w najprostszym trybie na wprowadzeniu zapytania, które chcemy wykonać, a następnie wciśnięciu przycisku „Wyszukaj”. Opis języka zapytań zamieszczamy na końcu tego dokumentu; najprostsze zapytanie o wszystkie segmenty składa się z pustego zestawu nawiasów kwadratowych []. Wyniki można ponadto ograniczać metadanymi (np. do określonej kadencji) podając je w panelu rozwijanym po naciśnięciu przycisku „Metadane”.
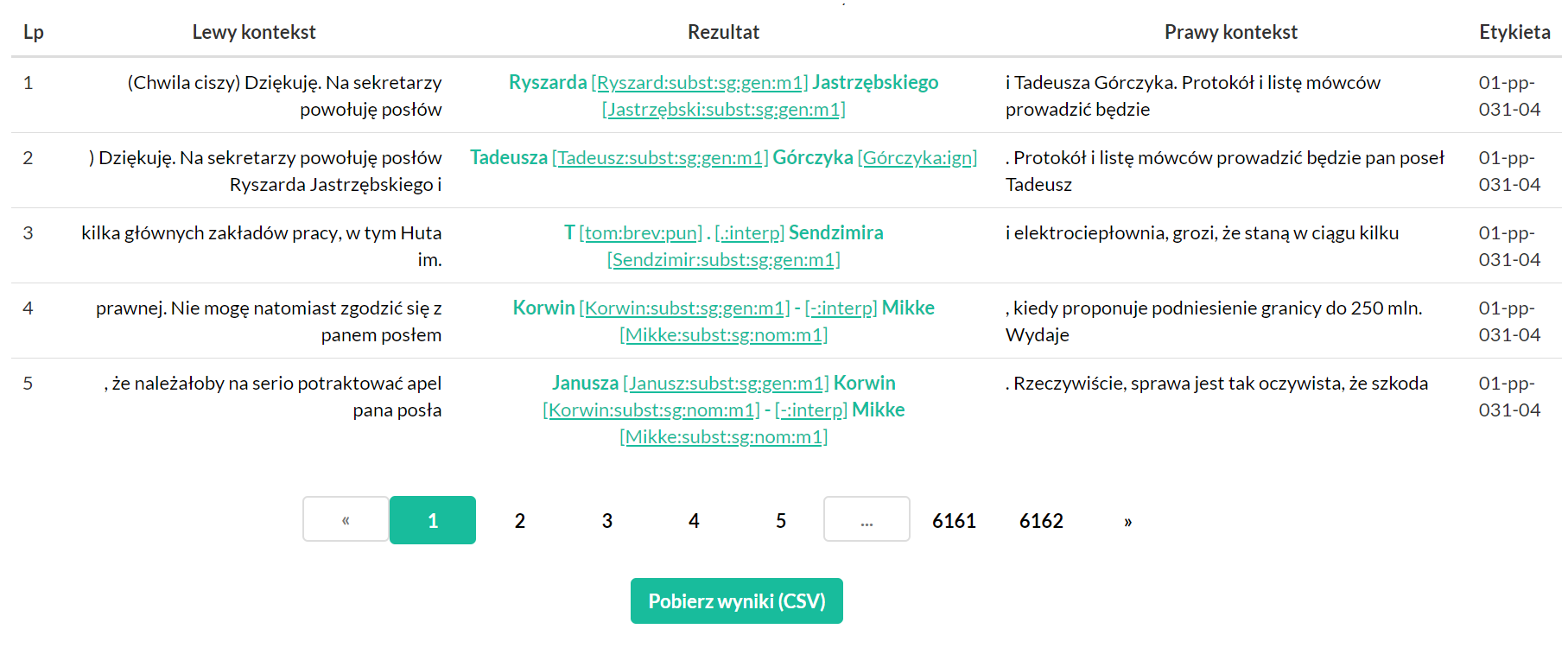
Po wykonaniu zapytania zostaniemy przeniesieni do strony z wynikami, które możemy przeglądać. Dodatkowo możemy wyświetlić dodatkowe informacje o kontekście znalezionego wyniku, klikając na niego lub pobrać całą listę wyników w formie pliku CSV.
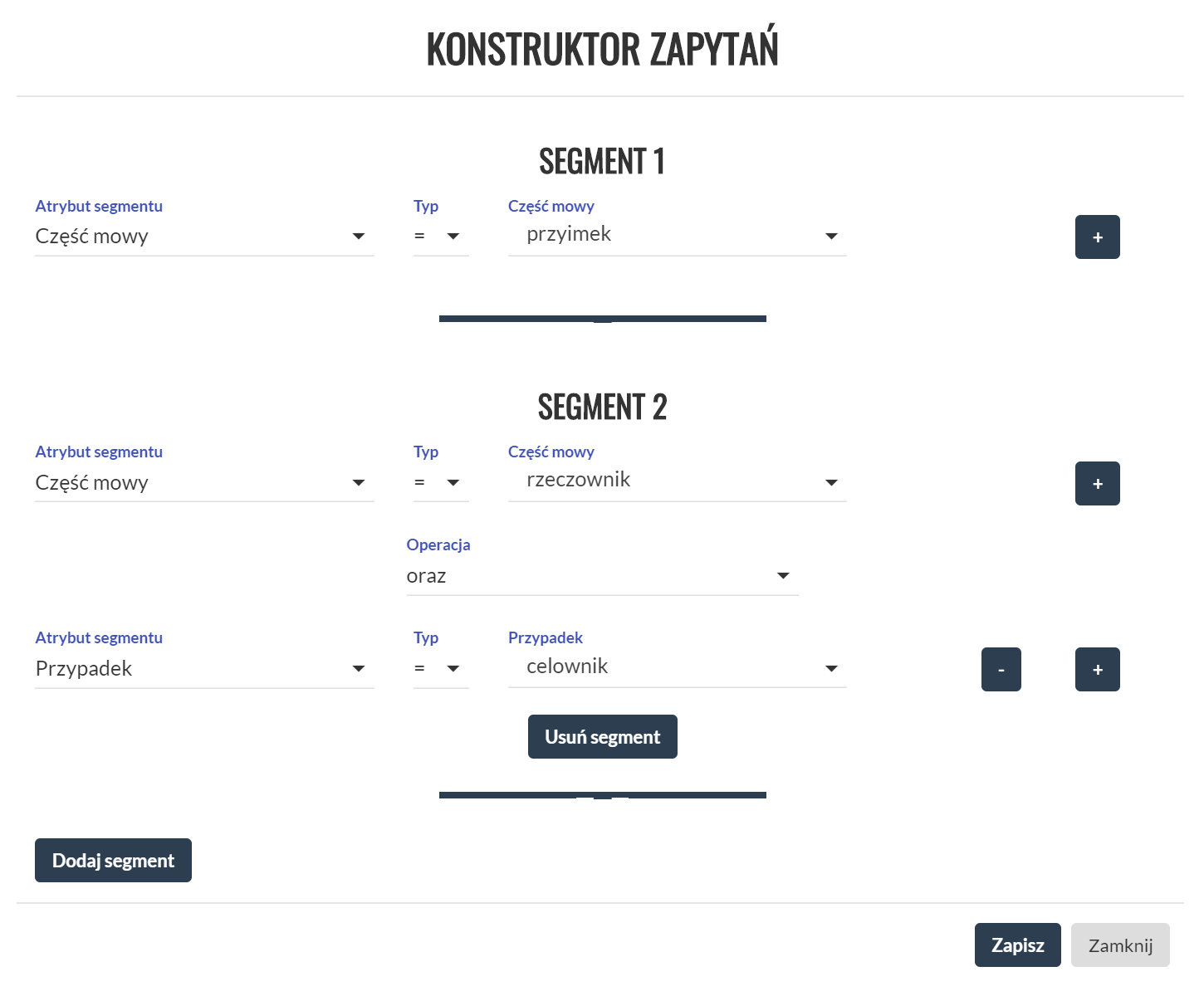
Konstruktor zapytań
Zapytania można tworzyć z pomocą graficznego konstruktora wybierając pożądane własności ciągu segmentów. Grafika ilustruje budowę zapytania wyszukującego w korpusie frazy przyimkowe z przyimkiem celownikowym składające się z przyimka i rzeczownika.
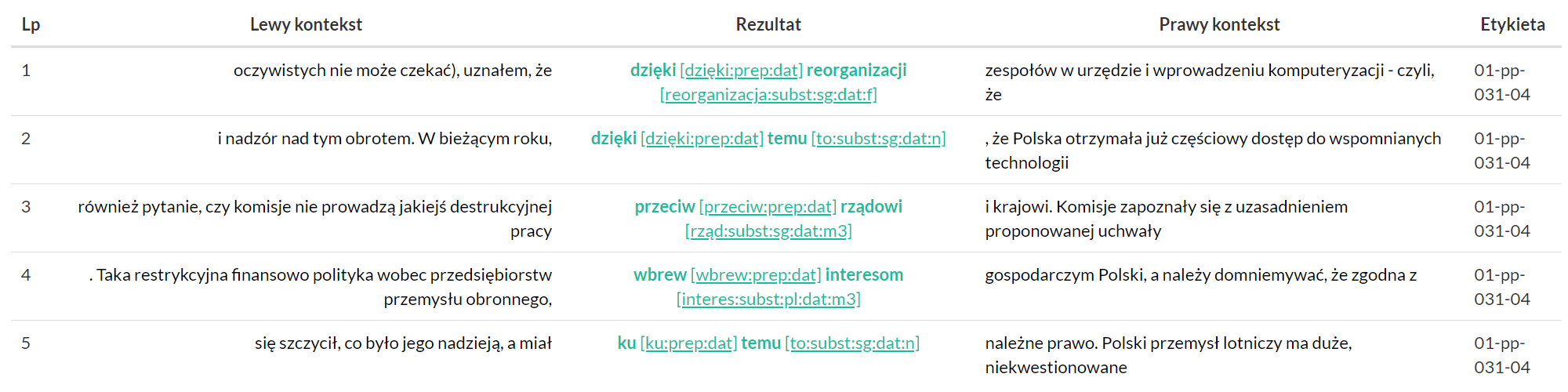
Stworzone zapytanie jest tłumaczone na język wyszukiwarki (dla naszego przykładu ma postać [pos="prep"][pos="subst"&case="dat"]), a następnie uruchamiane.
Opis lingwistyczny
Opis lingwistyczny korpusu został przejęty wprost z Narodowego Korpusu Języka Polskiego. Teksty korpusu anotowane są automatycznymi narzędziami analizy lingwistycznej na kilku poziomach: segmentacji na wypowiedzi, zdania i uogólnione słowa (segmenty), morfoskładni, słów i grup składniowych oraz nazw własnych.
Segmentami są zwykle słowa tekstowe (ciągi liter ograniczone spacjami lub znakami interpunkcyjnymi), w niektórych wypadkach dodatkowo rozdzielone na części zgodnie z ich podstrukturą morfoskładniową. Przypadki takiego podziału obejmują np. formy aglutynacyjne leksemu BYĆ (p. np. łgał|eś, długo|śmy, tak|em), partykuły by, -ż(e) i -li (przyszedł|by, napisała|by|m, chodź|że, potrzebował|że|by|ś, niechaj|że|ż, znasz|li), poprzyimkowe nieakcentowane formy zaimka -ń (do|ń, ze|ń) czy niektóre słowa zawierajace łącznik (polsko|-|niemiecki, Kowalska|-|Nowakowska, Jean|-|Pierre) — p. rozdział 6.2.2 z książki NKJP. Samodzielnymi segmentami są także znaki interpunkcyjne.
Warstwa morfoskładniowa przypisuje segmentom znaczniki określające ich formę podstawową (lemat), klasę gramatyczną oraz odpowiednie wartości kategorii gramatycznych. Repertuar klas i kategorii gramatycznych oparty jest na zbiorze klas i kategorii (tagsecie) stosowanym w analizatorze morfologicznym Morfeusz i opisanym w ściągawce do NKJP.
Język zapytań
Składnia zapytań wyszukiwarki jest zbliżona do składni wyszukiwarki Poliqarp wykorzystywanej m.in. do przeszukiwania NKJP.
Zapytania o segmenty i formy podstawowe wpisujemy w nawiasach kwadratowych według schematu: [atrybut="wartość"] (podając wartość w cudzysłowie). W najprostszych pytaniach o kształt tekstowy segmentu atrybutem będzie orth, a jego wartością — poszukiwany ciąg liter, np. [orth="Sejm"] (wielkość liter ma znaczenie). Aby znaleźć podane słowo niezależnie od wielkości poszczególnych liter, należy użyć atrybutu orth_lc, np. [orth_lc="sejm"]. Inne często używane atrybuty morfoskładniowe to number, case, gender, person, degree, aspect i negation (nazwy klas i kategorii gramatycznych najlepiej sprawdzać używając konstruktora zapytań lub angielskiej wersji ściągawki do NKJP).
Aby znaleźć wszystkie formy fleksyjne segmentu, należy użyć atrybutu base, np. [base="Polska"]. Wartością tego atrybutu jest forma podstawowa szukanego fleksemu, a zatem mianownik liczby pojedynczej dla rzeczowników czy bezokolicznik dla wszystkich fleksemów czasownikowych.
W zapytaniach o segmenty mogą wystąpić standardowe wyrażenia regularne z użyciem symboli:
- kropki zastępującej dowolny znak — np. wyrażenie bez. odpowiada segmentom beza, bezy, bezą itp., ale nie bez czy bezami,
- znaku zapytania oznaczającego opcjonalność poprzedniego znaku — wyrażenie beza? odpowiada segmentom bez lub beza,
- gwiazdki oznaczającej dowolną (także zerową) liczbę wystąpień znaku lub wyrażenia bezpośrednio przed nią — Ala.* odpowiada segmentom Ala i Alaska,
- nawiasów klamrowych oznaczających określoną liczbę wystąpień znaku lub wyrażenia poprzedzającego, np. tra(la){2,3} odpowiada segmentom tralala i tralalala.
Jeśli chcemy wyszukać kilka sąsiadujących ze sobą segmentów lub form podstawowych, każdą pozycję zapisujemy w oddzielnych nawiasach kwadratowych, czyli np. zapytanie [base="nasz"][base="niepodległość"] da w wyniku fragmenty tekstów zawierające wyrażenia „naszą niepodległość”, „naszej niepodległości” itd.
Oznaczając za pomocą pustych nawiasów kwadratowych dowolny segment, możemy znaleźć formy, które nie sąsiadują ze sobą bezpośrednio, np. zapytanie: [base="nasz"][]{1,2}[base="niepodległość"] odnajdzie w korpusie ciągi naszą gorzką ośmioletnią niepodległość czy naszą trudną niepodległość.
Atrybuty określane w zapytaniach można łączyć używając operatorów koniunkcji &, alternatywy | i negacji !. Zapytanie [orth="para" & !gender="f"] wyświetli zatem wszystkie wystąpienia słowa para, które nie są formami rodzaju żeńskiego (np. „krzyk godny wichrzycielskiego para XVII-wiecznej Francji, a nie generała demokratycznej Rzeczypospolitej”).
Zapytania o nazwy własne zadajemy w nawiasach kątowych podając typ nazwy własnej, np. <ne="persName"/>. Najprostszy sposób łączenia anotacji z różnych warstw to użycie filtra containing, np. nazwy osobowe w dopełniaczu wyszukamy uruchamiając zapytanie <ne="persName"/> containing [case="gen"].
Wypowiedzi określonego mówcy możemy wyszukać podając jego dane w następujący sposób: <u=".*Władysław Bartoszewski"/>. Wyrażenie regularne z kropką i gwiazdką umożliwia wykrycie wypowiedzi danej osoby występującej w różnych rolach (w przypadku Władysława Bartoszewskiego — Ministra Spraw Zagranicznych, Sekretarza Stanu w KPRM czy Senatora). Zapytania można także łączyć filtrami, np. wynikiem zapytania [base="człowiek"] within <u=".*Władysław Bartoszewski"/> będą segmenty o lemacie człowiek w wypowiedziach Władysława Bartoszewskiego.
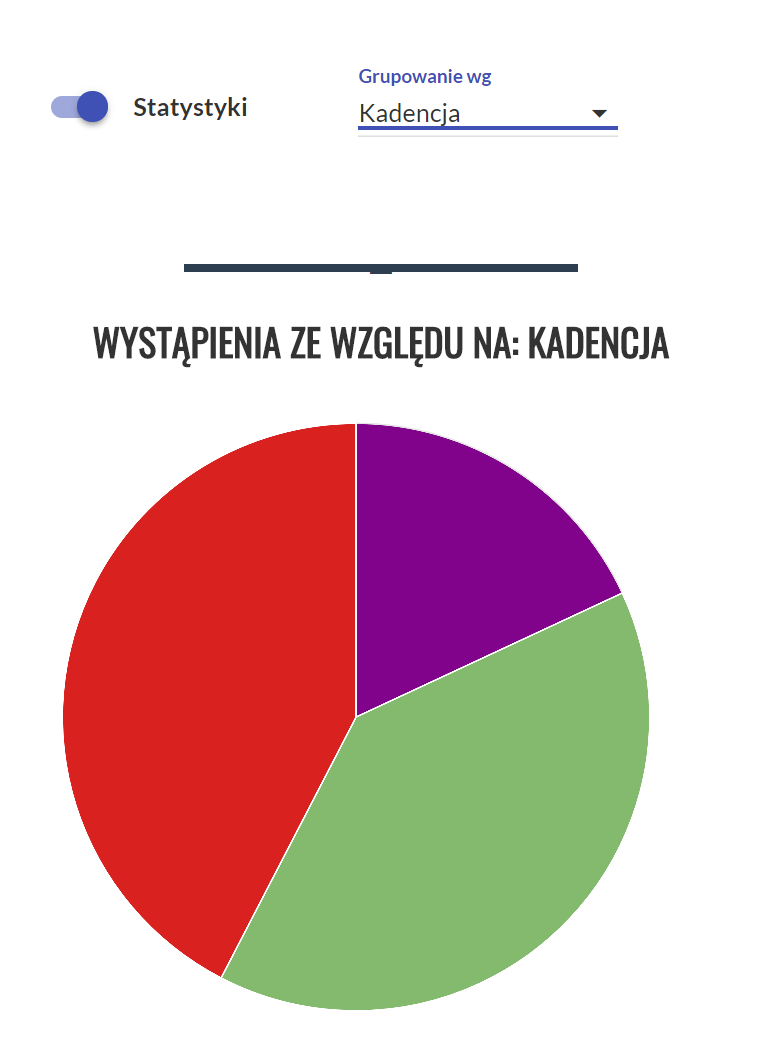
Statystyki
Kliknięcie przycisku „Statystyki” rozwija panel, w którym możemy włączyć grupowanie wyników względem określonych metadanych lub własności segmentów i np. wyświetlić udział prezentowanych wyników w poszczególnych kadencjach.
Wyszukiwanie tekstów
Wyszukiwanie tekstów polega na ew. ograniczeniu poszukiwań do wybranych metadanych i wciśnięciu przycisku „Wyszukaj”.
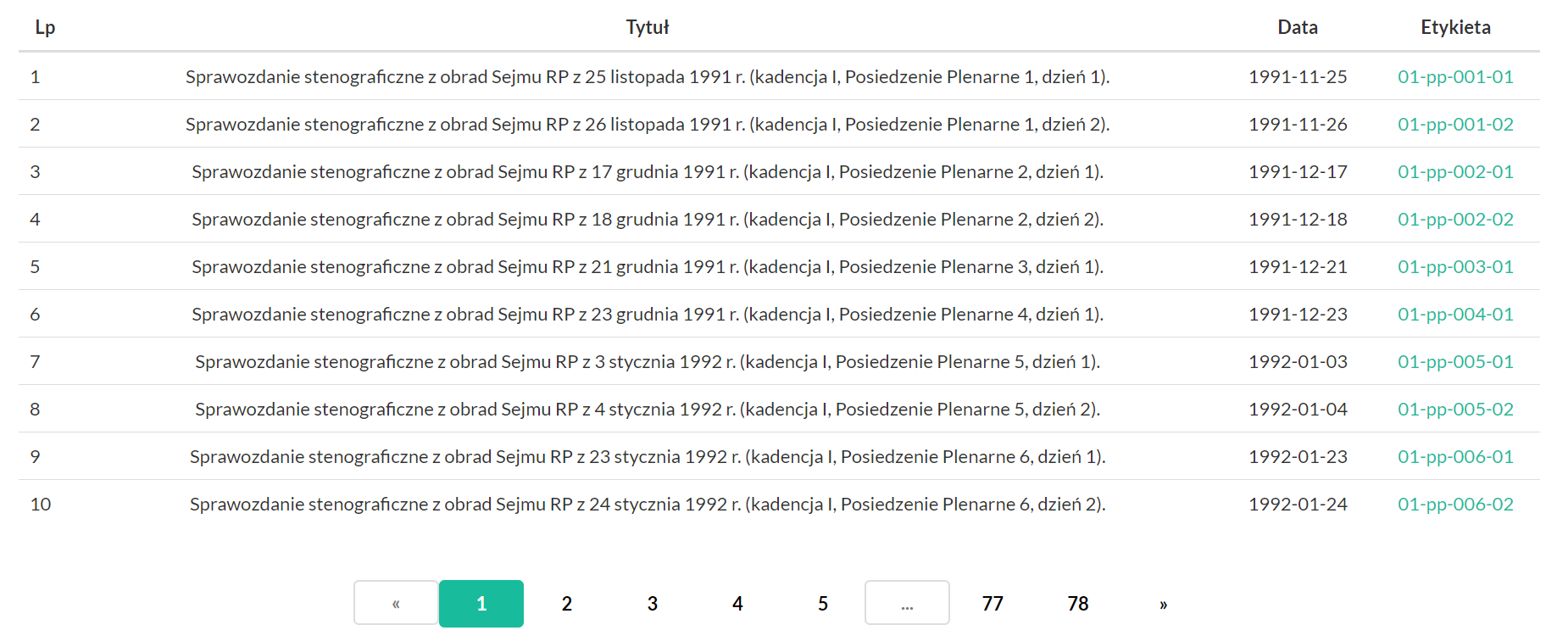
Po wykonaniu zapytania zostaniemy przeniesieni do strony z wynikami. Kliknięcie etykiety tekstu umożliwia pobranie archiwum zawierającego wszystkie warstwy anotacji lingwistycznej w formacie Narodowego Korpusu Języka Polskiego.
Podziękowania
Instrukcja powstała na bazie wcześniejszych dokumentów opisujących sposób użycia wyszukiwarki MTAS i zestaw znaczników Narodowego Korpusu Języka Polskiego, w szczególności Ściągawki do Narodowego Korpusu Języka Polskiego autorstwa Adama Przepiórkowskiego, Aleksandra Buczyńskiego i Jakuba Wilka, Instrukcji korzystania z wyszukiwarki do Elektronicznego Korpusu Tekstów Polskich z XVII i XVIII wieku (do 1772 r.) Włodzimierza Gruszczyńskiego i Renaty Bronikowskiej oraz Instrukcja korzystania z wyszukiwarki korpusu tekstów polskich z lat 1830-1918 i Instrukcji użytkownika Korpusomatu Witolda Kierasia.